Project Spring Fling
digital humanities for assessment @ auraria library
3.3. Contextualizing with Voyant
Voyant is an open-source text analysis tool developed by Stéfan Sinclair and Geoffrey Rockwell. It allows users to upload a corpus of text and use different micro-tools to visualize and analyze the text. Among other things, Voyant gives insight into word frequencies, trends, patterns, consistencies, relationships, correlations, and text density. It provides a space to dig into and experiment with a corpus of texts. In my case, the transcriptions of student responses from Spring Fling.
One of the micro-tools that I found most helpful for this corpus was TermsBerry. This tool contextualizes frequent words so you can see what words were used in conjunction with each other. This tool gives a similar result to topic modeling in that it shows what words were used together. The difference is that TermsBerry doesn’t combine these into a single topic; instead, it shows the number of times different words were used with the word-in-question. For example, the word “databases” was used near the word “resources” only once but near the word “research” twice.
With TermsBerry, I wanted to look at some of the words that were in both the student responses and the librarians' responses to see how often and in what context(s) they were used. I chose to look at those used frequently in the students’ responses (i.e. “library” and “resources”) and those used sparingly (i.e. “primary” and “articles”). The contexts were fairly enlightening. In all of the librarians' suggestions, these four words were often used to refer to information literacy concepts in addition to basic knowledge of library services. Librarians suggested knowing not only how to locate a primary source but how to identify one, for example. Current students wanted first-year students to know that there are a lot of resources at the library and that they can get help finding resources.
I also wanted to look at some words used only in the student responses (i.e. “printing” and “databases”). These two words were unique to this corpus, and I had remembered printing coming up fairly frequently while transcribing. I was surprised to see, though, that it wasn’t as popular as I had initially thought. I was also surprised to see that databases were not mentioned in the faculty suggestions at all. Students mentioned research and the online nature of databases, probably wanting first-year students to know that there are online databases that help with research.





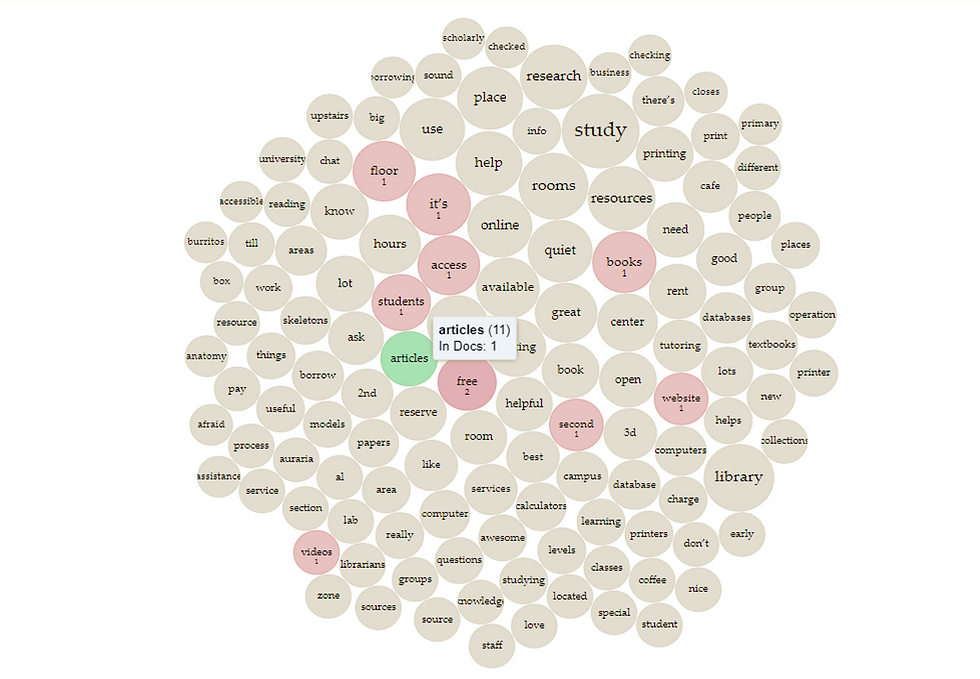
Contextualizing some of the frequent terms in this corpus (and some of the terms that were also in librarians' suggestions) added to my original attempt at topic modeling. This method also gave some insight into the ways in which students were using these terms and giving meaning to those usages. The overlap in librarians' and students' responses has no independent meaning, and TermsBerry helped create some of that missing piece.